Lazy Merkle Raffle
2023-04-16 • @kevincharm
Introduction
This article proposes a novel method of raffling (i.e. picking an arbitrary number of winners from an arbitrarily large list of participants) that is optimised for on-chain environments where storage and compute is expensive, by deferring the computation of winning indices until they are needed. This method applies the pull-over-push pattern that is commonly employed in airdrops, where recipients must claim their airdrop share rather than receiving it directly in their wallets.
Using this new method of raffling, for a raffle picking winners from some arbitrarily large list of participants, a winner must claim her winning ticket using a Merkle proof where is the leaf index of the winner and is the ordered set of sibling hashes in the path needed to reconstruct the Merkle root. The index is then bijectively mapped to a shuffled index using a cycle-walking Feistel cipher and a committed secure random seed . The win is then valid iff .
Merkle Trees for Proving Inclusion and Index
Merkle trees are magical data structures that can be used to compress arbitrarily large lists into a single hash (also known as the Merkle root). This property makes them useful for verifying the integrity of large data sets.
Merkle proofs are used to succinctly prove that an item belongs to an arbitrarily large list by constructing a path from the item to the Merkle root. However, what is not commonly known is that Merkle proofs can also prove the index of that item in the list, given the correct proof format.
Preparing the Merkle tree
To prepare a list of participants for a raffle, we first construct a Merkle tree of depth using the raffle participants as the leaves, filling the remaining empty leaves with a zero value . Leaf indices should correspond to their positional index in the original participants list . Figure 2 illustrates how the participants list from Figure 1 should be constructed as a Merkle tree.
| index | participant |
|---|---|
| 0 | a |
| 1 | b |
| 2 | c |
Generating the Merkle proof
With the Merkle tree constructed, it is then possible to generate Merkle proofs to prove the inclusion and the index of each leaf. Figure 3 shows the components of the Merkle proof of the 2nd leaf c derived from the Merkle tree in Figure 2.
For a leaf in a Merkle tree of depth , a root , and a collision-resistant cryptographic hash function , a prover constructs a Merkle proof , where denotes the consecutive sibling nodes required as inputs to on each level, with the corresponding bit of determining the order of inputs to , to reconstruct that convinces a verifier that is the leaf of .
Lazy Shuffling
At the core of any raffling algorithm is the shuffle that produces an unpredictable permutation of the list of participants. The problem with array-based shuffling algorithms, such as the Fisher-Yates algorithm, is that they require stateful computation to produce the final list of winners. On the EVM, this requires writing multiple times to storage, which makes the algorithm economically expensive. Therefore, there is a need to use a different class of shuffling algorithms - we will refer to this class of algorithms as stateless shuffles.
Given a finite ordered set with elements , and a random seed , a stateless shuffle function maps with a permutation .
It is important that these stateless shuffle algorithms strictly produce permutations of the set of participants in order to enforce the property that raffle winners are drawn without repetition. Figure 4 gives an example of how applying a stateless shuffle function to each element in a finite set produces a bijective mapping .
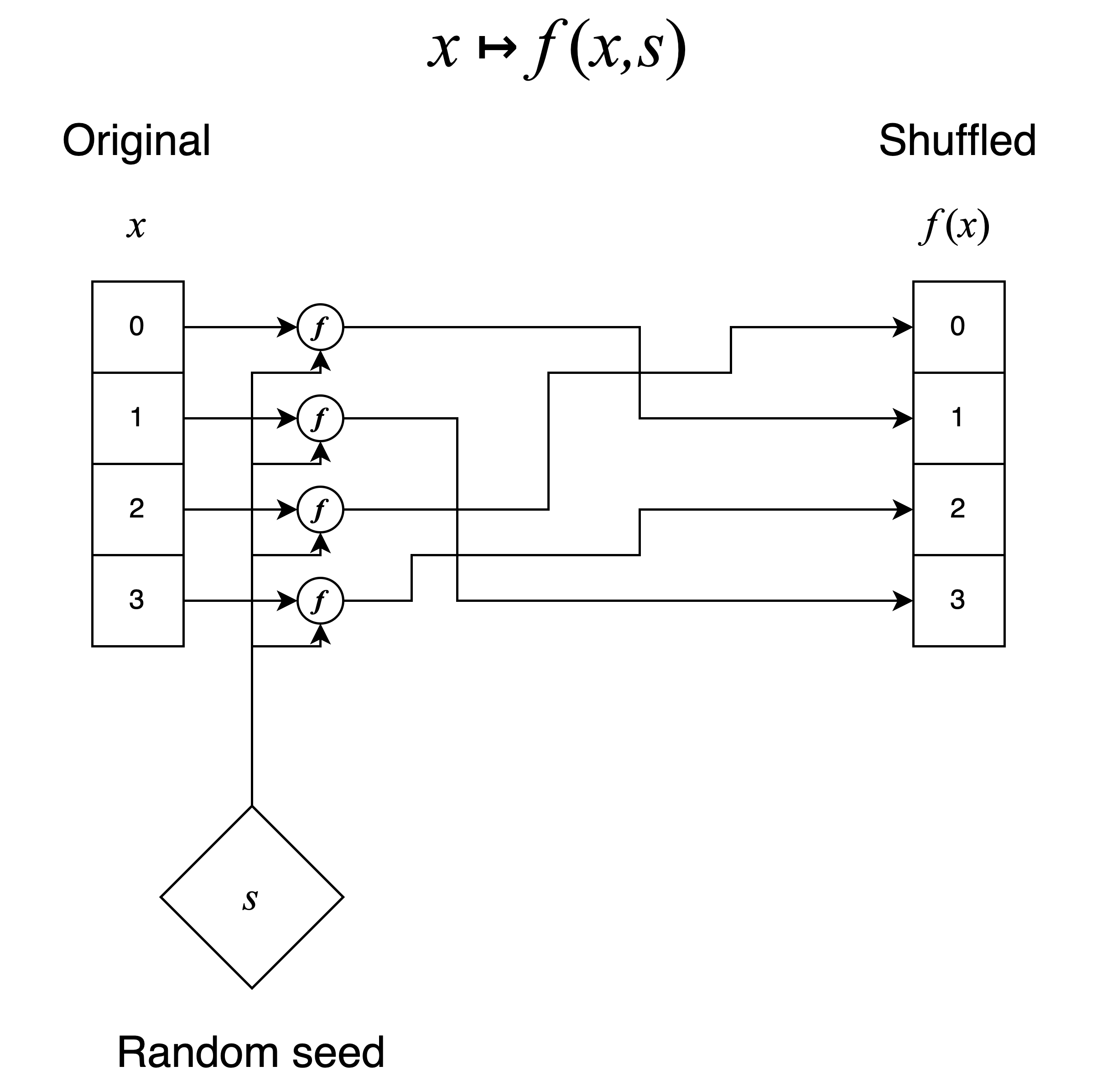
There exists an algorithm to deterministically (based on a given seed) compute a bijective mapping of an index to its shuffled index. In fact, there are at least 2 known algorithms: The Swap-or-not Shuffle and the Feistel Shuffle. Specifically, we use the Feistel Shuffle with rounds set to 4 as it is the most economical of the stateless shuffling algorithms when implemented for the EVM. Of course, an unpredictable secure random seed is still required as an input to these shuffling algorithms.
The Feistel Shuffle
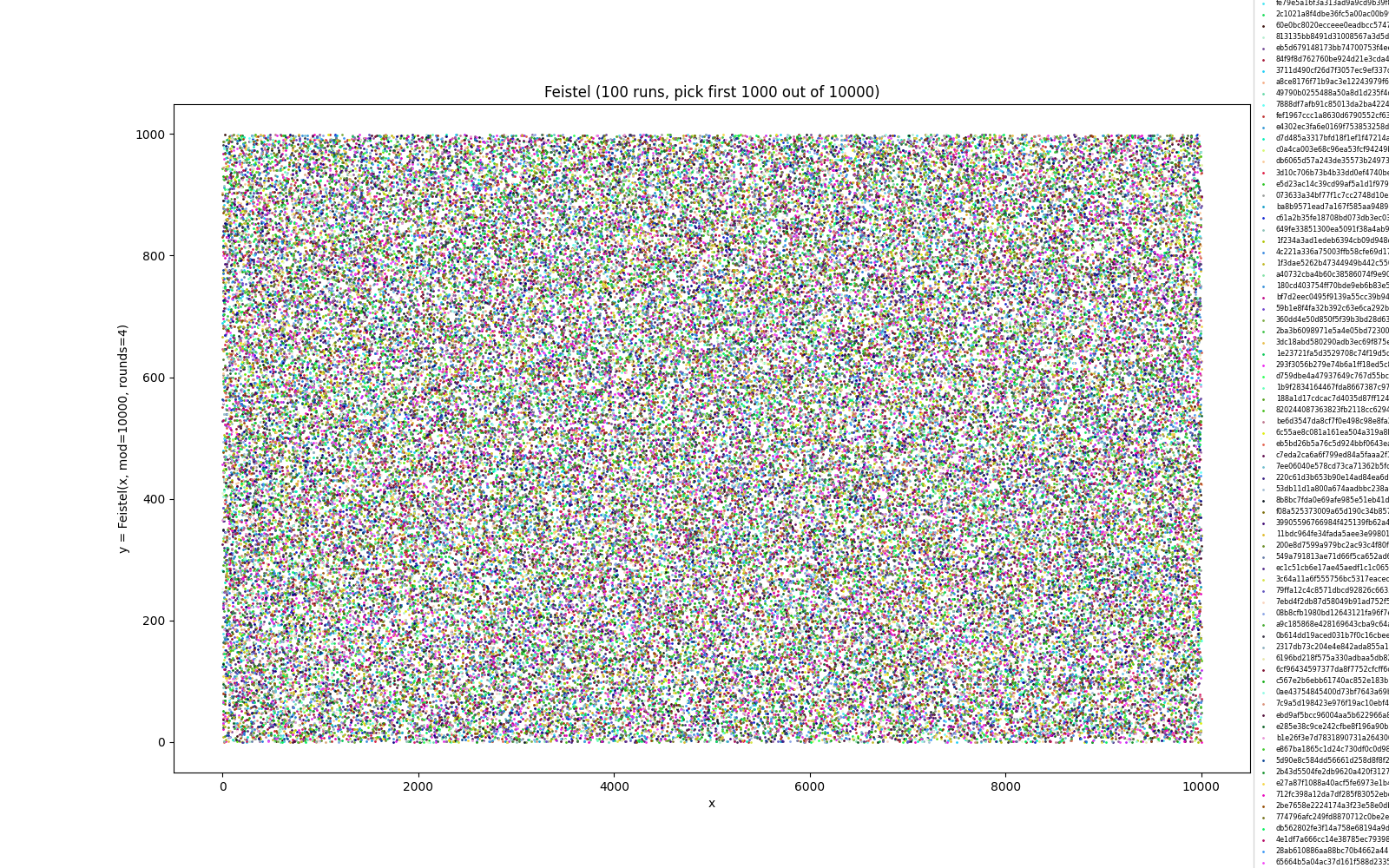
The Feistel Shuffle can cheaply be implemented in the EVM, coming in at ~4350 gas to calculate a permutation for a single index for a list size of 10,000. Feistel ciphers are based on round functions, and these are run a fixed number of times, as specified in the rounds parameter. It is sufficient to set rounds = 4 to make a strong pseudorandom permutation, given a cryptographically secure random seed is used (discussed in this paper by Luby & Rackoff). The Feistel Shuffle was a candidate for computing validator committees in Ethereum Proof-of-Stake consensus specifications with the desired properties of having a distribution being provably close to uniform; and the ability to compute a shuffled index in .
An example of the distribution of the outputs of a correctly-configured Feistel Shuffle function is shown in Figure 5.
Verifying Winners Just-In-Time
As discussed previously, the winners of a raffle are defined as those participants whose shuffled indices are less than the number of winners to be picked.
Given a raffle picking winners with an ordered set of participants , and a committed random seed , the ordered set of winners is .
While it is possible to eagerly map a stateless shuffle function over the entire set of participants, we can defer this computation to the moment when raffle participants check whether they've won or not. Upon checking whether an entry is indeed a winning entry, a participant first generates a Merkle proof that proves both the inclusion and the index of the entry in the original participants list. This index is then applied as an input to the stateless function along with the committed random seed . If the number of winners to pick in the raffle is , then the participant holds a winning entry iff .
Most importantly, this verification can be efficiently performed just-in-time inside a smart contract while a participant attempts to claim a prize. The gas overhead of this verification operation on the EVM is equivalent to verification of a Merkle proof plus a few thousand gas for performing a Feistel shuffle.